
AWS Kinesis Data Streams vs. Kinesis Data Firehose

The AWS Kinesis Platform offers four services: Kinesis Video Streams (which can capture, process, and store live media data), Kinesis Data Streams (which can capture, process, and store real-time data), Kinesis Data Firehose (which can load real-time data streams into data storage), and Kinesis Data Analytics (which can analyze real-time data with SQL). AWS Kinesis Data Streams may be considered as a cloud-native service of Apache Kafka. In the last post, we compared Apache Kafka and AWS Kinesis Data Streams. These three data set services — Kinesis Data Streams, Kinesis Data Firehose, and Kinesis Data Analytics — can work together to perform the real-time analysis.
Data Flows
One may see different combinations of these three data set services such as:
- Input -> Kinesis Data Streams -> Kinesis Data Analytics, Spark on EMR, you consume code on EC2, or Lambda function -> Output
- Input -> Kinesis Data Firehose -> AWS S3, AWS Redshift, AWS Elasticsearch Service (ES), or Splunk -> Output
- Input -> Kinesis Data Streams or Kinesis Data Firehose -> Kinesis Data Analytics -> Output
- Input -> Kinesis Data Streams -> Kinesis Data Analytics -> Kinesis Data Firehose and/or Kinesis Data Streams -> Process or store data -> Output
- Input -> Kinesis Data Streams -> Kinesis Data Firehose -> Store data for Analytics ->Output
For example, consider the Streaming Analytics Pipeline architecture on AWS: one can either analyze the stream data through the Kinesis Data Analytics application and then deliver the analyzed data into the configured destinations or trigger the Lambda function through the Kinesis Data Firehose delivery stream to store data into S3.

Another example mentioned in the AWS document is that you can configure Amazon Kinesis Data Streams to send information to a Kinesis Data Firehose delivery stream. After that, you can also use Kinesis Data Analytics or other Kinesis Data Streams which depends on the use case. Concerning data streaming buffer, both Data Streams and Data Firehose can fulfill this task. Thus, in this post, we will compare Kinesis Data Streams (KDS) and Kineses Data Firehose (KDF).
Kinesis Data Set of Services
Let’s take a quick look at the architectures of the three services:
Kinesis Data Streams
A model of the architecture of Kinesis Data Streams is shown below:
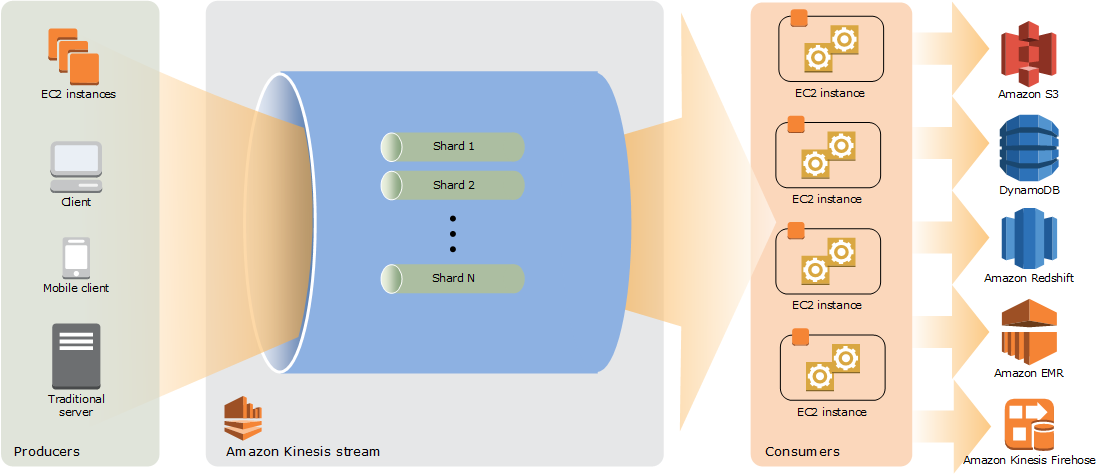
- The producers put records (data ingestion) into KDS. AWS provides Kinesis Producer Library (KPL) to simplify producer application development and to achieve high write throughput to a Kinesis data stream.
- A Kinesis data Stream is a set of shards. Each shard has a sequence of data records. Data records are composed of a sequence number, a partition key, and a data blob (up to 1 MB), which is an immutable sequence of bytes.
- The consumers get records from Kinesis Data Streams and process them. You can build your applications using either Kinesis Data Analytics, Kinesis API or Kinesis Client Library (KCL).
Kinesis Data Firehose
A model of the architecture of Kinesis Data Firehose is shown below:

- Data producers send records to Kinesis Data Firehose delivery streams.
- The underlying entity of Kinesis Data Firehose is Kinesis Data Firehose delivery stream. It automatically delivers the data to the destination that you specified (e.g. S3, Redshift, Elasticsearch Service, or Splunk)
- You can also configure Kinesis Data Firehose to transform your data before delivering it. Enable Kinesis Data Firehose data transformation when you create your delivery stream. Then Kinesis Data Firehose invokes your Lambda function to transform incoming source data and deliver the transformed data to destinations.
Kinesis Data Analytics
A model of the architecture of Kinesis Data Analytics is shown below:
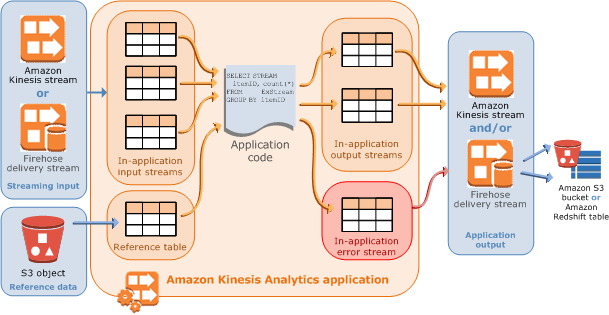
- Kinesis Data Analytics applications continuously read and process streaming data from Data Streams or Data Firehose in real time. In the input configuration, you map the streaming source to an in-application input stream.
- You write application code using SQL to process the incoming streaming data and produce output. You can write SQL statements against in-application streams and reference tables. You can also write JOIN queries to combine data from both of these sources.
- Kinesis Data Analytics then writes the output to a configured destination. External destinations can be a Kinesis Data Firehose delivery stream or a Kinesis data stream. You can configure a Kinesis Data Firehose delivery stream to write results to AWS S3, Redshift, or Elasticsearch Service (ES). You can also specify a Kinesis data stream as the destination with AWS Lambda to poll the stream to your custom destination.
Comparison
| Concepts | AWS Kinesis Data Firehose | AWS Kinesis Data Streams |
| Provision | No pre-provision | Configure the number of shards |
| Scale/Throughput | No limit ~ Automatic | No limit ~ Shards |
| Data Retention | N/A (Up to 24 hours in case the delivery destination is unavailable. Data can be delivered to AWS S3, Redshift, Elasticsearch Service and Splunk) | 1 to 7 days (default is 24 hours) |
| Delivery | At least once semantics | Same |
| Multiple Consumers | No (Data can be delivered to AWS S3, Redshift, Elasticsearch Service and Splunk) |
Yes |
| Record/Object Size | 1000KiB | 1MB |
| Availability | Three AZs | Same |
| Security | Data can be secured at-rest by using server-side encryption and AWS KMS master keys on sensitive data within KDS. Access data privately via your Amazon Virtual Private Cloud (VPC) | Same |
| Monitoring | AWS Cloudwatch, CloudTrail and Kinesis Analytics | Same |
| Cost | Pay and use. | Pay and use. Setup in a couple Of hours |
Conclusion
AWS Kinesis Data Streams enables one to build custom applications that process or analyze streaming data for specialized needs by providing the streaming buffer needed and allowing you to write the custom code with business logic. However, with Kinesis Data Firehose, one doesn’t need to write applications or manage resources. One can configure Kinesis Data Firehose to transform data with the Lambda function. Note that one can take full advantage of the Kinesis data set services by using all three of them or combining any two of them (e.g., configuring Amazon Kinesis Data Streams to send information to a Kinesis Data Firehose delivery stream, transforming data in Kinesis Firehose, or processing the incoming streaming data with SQL on Kinesis Data Analytics).




Which flow is possible?
1) Convert data stream by Kinesis Analytics ? (input -> Kinesis Data Streams -> Kinesis Data Analytics-> back to Kinesis Data Streams -> my consumer service -> output )
2)Convert by Kinesis Firehose and send back to Kinesis Data Streams (input -> Kinesis Data Streams -> Kinesis Firehose -> back to Kinesis Data Streams -> my consumer service -> output )
Main point i need to parse and transform data to my format and send it in stream . As i understand the Firehose has to save result to DB , so it’s not satisfied me ….