
When Should Use Amazon DynamoDB Accelerator (AWS DAX)?
The main purpose of Amazon DynamoDB Accelerator (AWS DAX) is in-memory cache. DAX manages cache invalidation, data population, or cluster management. So it can deliver up to a 10x performance improvement – from milliseconds to microseconds – even at millions of requests per second.
AWS DAX Architecture Overview
Amazon DynamoDB Accelerator (DAX) is a fully managed, highly available, in-memory cache for DynamoDB. Please review the architecture diagram from AWS:
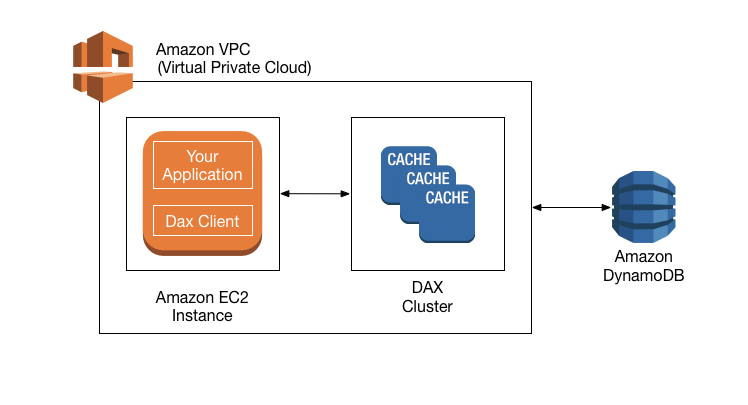
From the diagram, we can see DAX, applications and DAX client are in the same Virtual Private Cloud (VPC) environment. So DAX is designed to run within a VPC in order to utilize VPC’s subnets, routing tables, network gateways, and security settings. A DAX cluster consists of one or more nodes. Each node runs its own instance of the DAX caching software. One of the nodes serves as the primary node for the cluster. Additional nodes if present serves as the read replicas. At runtime, the DAX client directs all of your application’s DynamoDB API requests to the DAX cluster. If DAX can process one of these API requests directly, it does so; otherwise, it passes the request through to DynamoDB. Finally, the DAX cluster returns the results to your application.
Types of Caches in AWS DAX
There are two types of caches in AWS DAX:
- Item cache: DAX maintains an item cache to store the results from GetItem and BatchGetItem operations. The items in the cache represent eventually consistent data from DynamoDB and are stored by their primary key values.
- Query cache: DAX maintains a query cache to store the results from Query and Scan operations. The items in this cache represent result sets from queries and scans on DynamoDB tables. These result sets are stored by their parameter values.
AWS DAX Flow Diagram
There are two categories of these APIs. Read APIs include GetItem, BatchGetItem, Query, and Scan. Modify APIs include PutItem, UpdateItem, DeleteItem, and BatchWriteItem
Let’s take a look at the flow diagram on DAX to read/write operations:
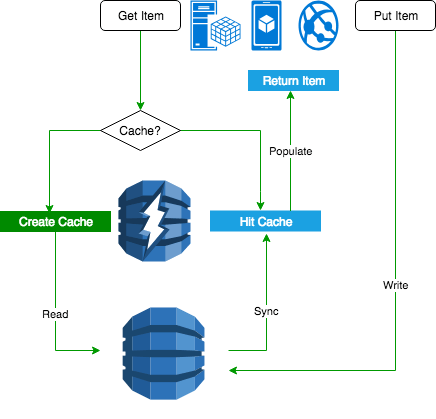
The left side is read through. When your application requests the read operation, there is no cache for the first time. DAX creates a cache and reads data from DynamoDB. Then in the second time, the application will hit the cache and return the item back to the application. The right side is the example of write through. The application writes data directly into DynamoDB. DAX sync the data in the cache. Then next time, the application will hit the cache to get the results.
Conclusion
AWS DAX provides a way to do in-memory cache. DAX reduces the response times of eventually-consistent read workloads from single-digit milliseconds to microseconds. DAX does increase throughput and save cost by reducing the need to over-provision read capacity units. However, If your applications that require strongly consistent reads or write-intensive, then you should not use DAX. If you need more details on DynamoDB, please review it in Hands-on with DynamoDB.



