
Streaming Platforms: Apache Kafka vs. AWS Kinesis

Apache Kafka and AWS Kinesis are two real-time data streaming platforms. Both have excellent features to support the needs of businesses concerning real-time streams of data collection and analytics. But how do you choose between the two? In this article, I will compare Apache Kafka and AWS Kinesis.
Apache Kafka
Apache Kafka is an open-source stream-processing software platform developed by Linkedin, donated to Apache Software Foundation, and written in Scala and Java. APIs allow producers to publish data streams to topics. A topic is a partitioned log of records with each partition being ordered and immutable. Consumers can subscribe to topics. Kafka can run on a cluster of brokers with partitions split across cluster nodes.
Kafka has five core APIs:
- The Producer API allows applications to send streams of data to topics in the Kafka cluster.
- The Consumer API allows applications to read streams of data from topics in the Kafka cluster.
- The Streams API allows transforming streams of data from input topics to output topics.
- The Connect API allows implementing connectors that continually pull from some source system or application into Kafka or push from Kafka into some sink system or application.
- The AdminClient API allows managing and inspecting topics, brokers, and other Kafka objects.
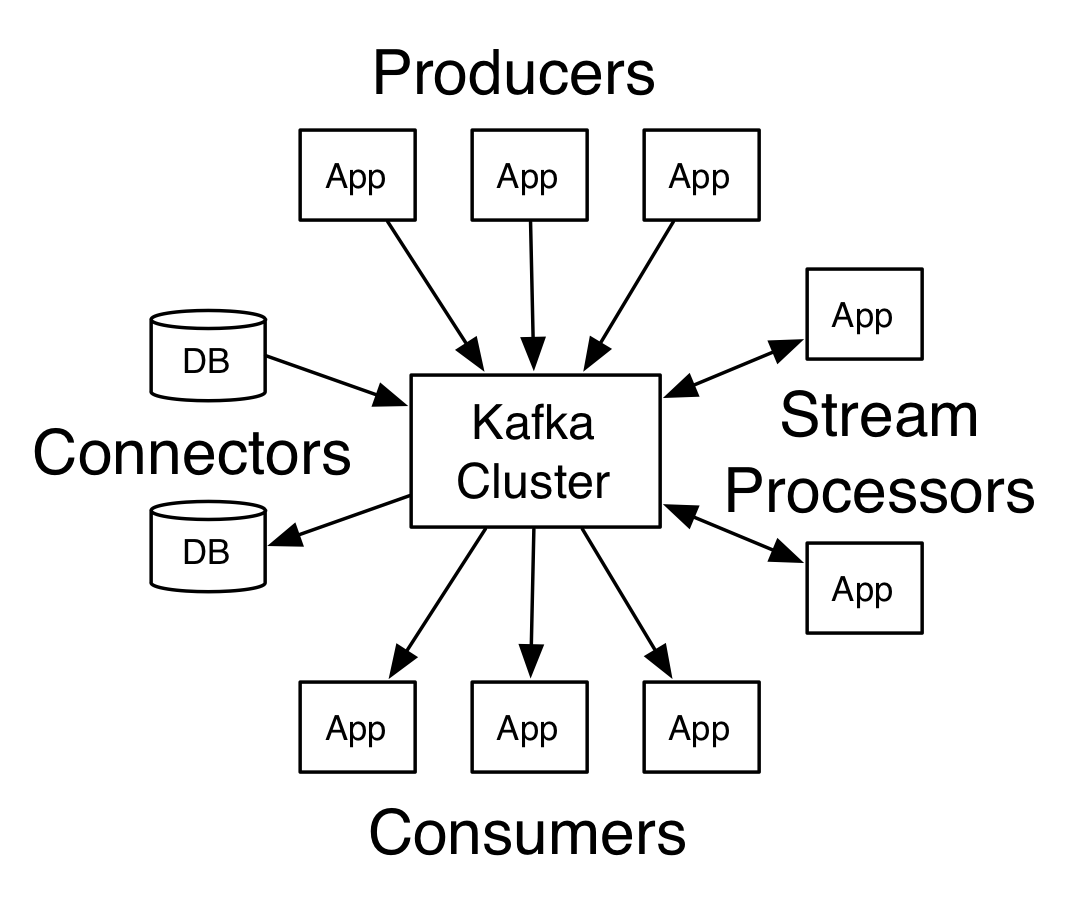
Kafka has the following feature for real-time streams of data collection and big data real-time analytics:
- Performance: Works with the huge volume of real-time data streams. Handles high throughput for both publishing and subscribing
- Scalability: Highly scales distributed systems with no downtime in all four dimensions: producers, processors, consumers, and connectors
- Fault tolerance: Handles failures with the masters and databases with zero downtime and zero data loss
- Data Transformation: Offers provisions for deriving new data streams using the data streams from producers
- Durability: Uses Distributed commit logs to support messages persisting on disk
- Replication: Replicates the messages across the clusters to support multiple subscribers
As a result, Kafka aims to be scalable, durable, fault-tolerant, and distributed. However, Kafka requires some human support to install and manage the clusters. Also, the extra effort by the user to configure and scale according to requirements such as high availability, durability, and recovery.
AWS Kinesis
Amazon Kinesis has four capabilities: Kinesis Video Streams, Kinesis Data Streams, Kinesis Data Firehose, and Kinesis Data Analytics. The Kinesis Data Streams can collect and process large streams of data records in real time as same as Apache Kafka. AWS Kinesis offers key capabilities to cost-effectively process streaming data at any scale, along with the flexibility to choose the tools that best suit the requirements of your application. It enables you to process and analyze data as it arrives and responds instantly instead of having to wait until all your data is collected before the processing can begin. Let’s focus on Kinesis Data Streams(KDS).
The high-level architecture on KDS:
- The producers put records (data ingestion) into KDS. AWS provides Kinesis Producer Library (KPL) to simplify producer application development and to achieve high write throughput to a Kinesis data stream.
- A Kinesis data Stream a set of shards. Each shard has a sequence of data records. Data records are composed of a sequence number, a partition key, and a data blob (up to 1 MB), which is an immutable sequence of bytes.
- The consumers get records from Kinesis Data Streams and process them. You can build your applications using either Kinesis Data Analytics, Kinesis API or Kinesis Client Library (KCL).
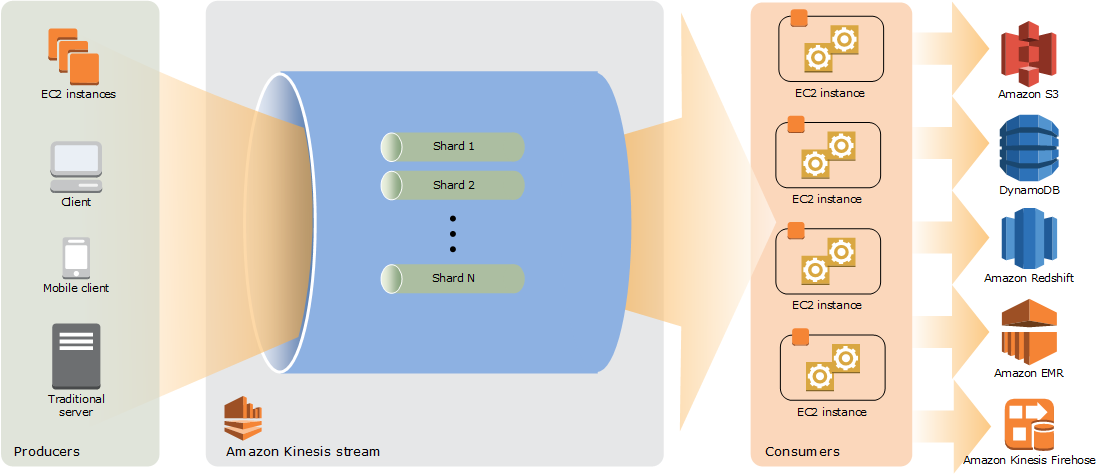
KDS has the following benefits:
- Fully managed: Kinesis is fully managed and runs your streaming applications without requiring you to manage any infrastructure
- Scalability: Handle any amount of streaming data and process data from hundreds of thousands of sources with very low latencies
- Durability: KDS application can start consuming the data from the stream almost immediately after the data is added.
- Elasticity: Scale the stream up or down, so the data records never lose before they expire
- Fault tolerance: The Kinesis Client Library enables fault-tolerant consumption of data from streams and provides scaling support for KDS applications
- Security: Data can be secured at-rest by using server-side encryption and AWS KMS master keys on sensitive data within KDS. Access data privately via your Amazon Virtual Private Cloud (VPC)
As a result, KDS is massively scalable and durable, allowing rapid and continuous data intake and aggregation; however, there is a cost for a fully managed service. KDS has no upfront cost, and you only pay for the resources you use (e.g., $0.015 per Shard Hour.) Please check Amazon for the latest KDS pricing.
Key Concepts Comparison
| Concepts | Apache Kafka | AWS Kinesis Data Streams |
| Data Storage | Partitions | Shards |
| Data Ordering | In partition level | In shard level |
| Data Retention | No maximum (configurable) | 1 to 7 days (default is 24 hours) |
| Data Size Per Blob | Default 1MB (but can be configured) | Maximum 1 MB |
| Partition/Shard Modification | Increase only and does not repartition existing data | Re-shard by merging or splitting shards |
| Partition/Shard Limitation | No limit. Optimal partitions depend on the use case | 500 shards in US East (N. Virginia), US West (Oregon), and EU (Ireland) regions. 200 shards in all other regions. |
| Data Replication/DR | Cluster mirroring | Automatically across 3 Availability Zones |
| Message Delivery Semantics | Kafka guarantees at-least-once delivery by default. Kafka supports exactly-once delivery in Kafka Streams | Kinesis Data Streams has at least once semantics |
| Security | Either SSL or SASL and authentication of connections to Kafka Brokers from clients; authentication of connections from brokers to ZooKeeper; data encryption with SSL/TLS | Data can be secured at-rest by using server-side encryption and AWS KMS master keys on sensitive data within KDS. Access data privately via your Amazon Virtual Private Cloud (VPC) |
| Monitoring | Yammer Metrics for metrics reporting in the server | AWS CloudWatch and CloudTrail |
| Dependency | ZooKeeper | DynamoDB |
| Cost | Requires a lot of human support on installation, set up, configuration and clusters management. Setup in weeks | Pay and use. Setup in a couple Of hours |
Conclusion
Both Apache Kafka and AWS Kinesis Data Streams are good choices for real-time data streaming platforms. If you need to keep messages for more than 7 days with no limitation on message size per blob, Apache Kafka should be your choice. However, Apache Kafka requires extra effort to set up, manage, and support. If your organization lacks Apache Kafka experts and/or human support, then choosing a fully-managed AWS Kinesis service will let you focus on the development. AWS Kinesis is catching up in terms of overall performance regarding throughput and events processing. When moving from Apache Kafka to AWS cloud service, you can set up Apache Kafka on AWS EC2. To avoid any challenge — such as setup and scale — and to manage clusters in production, AWS offers Managed Streaming for Kafka (MSK) with settings and configuration based on Apache Kafka’s best deployment practices. MSK is public preview now and will GA in the first quarter of this year.



