
Data Warehouse Cloud Solutions: AWS Redshift vs. GCP BigQuery

AWS and GCP provide impressive cloud data warehouse solutions with Redshift and BigQuery. Each of these solutions can run analytic queries against petabytes to exabytes of data with highly-scalability, cost-effective and secure. I will compare the two solutions and you can choose the option based on your use cases.
Architecture
Both AWS Redshift and GCP BigQuery are petabyte-scale, columnar-storage data warehouses. They are specifically designed for online analytical processing (OLAP) and business intelligence (BI) applications.
AWS Redshift
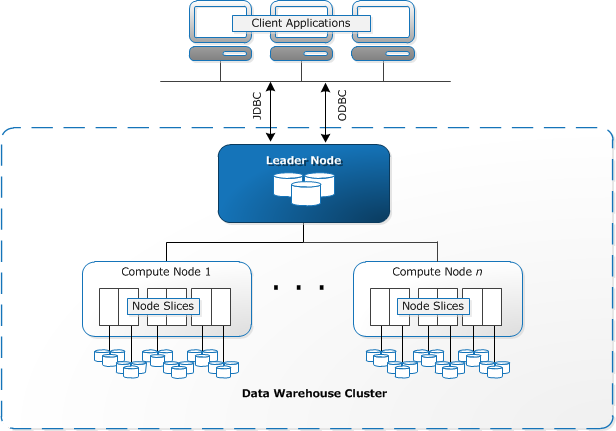
AWS Redshift Data Warehouse solution is based on PostgreSQL but beyond just PostgreSQL. The core infrastructure component of an AWS Redshift data warehouse is a cluster. A compute node is partitioned into slices. Each slice is allocated a portion of the node’s memory and disk space, where it processes a portion of the workload assigned to the node. A cluster is composed of one or more compute nodes. If a cluster is provisioned with two or more compute nodes, an additional leader node coordinates the compute nodes and handles external communication.
The client applications interact directly only with the leader node. The compute nodes are transparent to external applications. A compute node is partitioned into slices. Each slice is allocated a portion of the node’s memory and disk space, where it processes a portion of the workload assigned to the node. The leader node manages to distribute data to the slices and apportions the workload for any queries or other database operations to the slices. The slices then work in parallel to complete the operation. A cluster contains one or more databases. User data is stored on the compute nodes. AWS Redshift introduces Redshift Spectrum that directly performs SQL queries on data stored in the AWS S3 bucket. This can save time and money without moving data from a storage service to the data warehouse.
GCP BigQuery
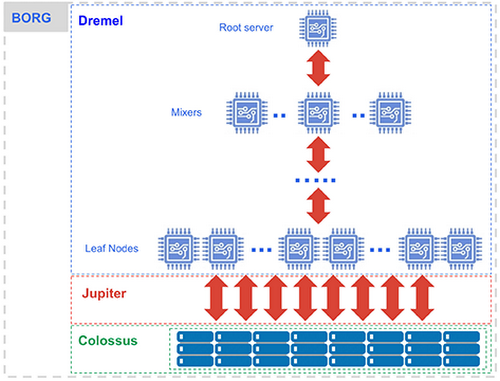
GCP BigQuery Data Warehouse solution is built on top of Dremel technology. Dremel is a distributed SQL query engine that can perform complex queries over data stored on GFS, Colossus, and others. The client applications interact with the Dremel engine via a client interface. Dremel implements a multi-level serving tree to execute queries. The leaves of the tree are slots. Slots do the heavy lifting of reading the data from the distributed storage system Colossus and doing any computation necessary. The branches of the tree are mixers. Mixers perform the aggregation.
BigQuery leverages Google’s Jupiter network to move data extremely rapidly from one place to another. The mixers and slots are all run by Borg. Borg is Google’s large-scale cluster management system that allocates the compute capacity for Dremel jobs. BigQuery architecture separates the concepts of distributed storage system Colossus and the computing system Borg. This architecture allows both storage and computing to scale independently for an elastic data warehouse.
Features
AWS Redshift and GCP BigQuery are both platforms as a service in the cloud. Let’s compare the features in the following areas:
| Features | AWS Redshift | GCP BigQuery |
| Infrastructure Management | Fully managed. Automated provisioning and automated backup | Completely serverless. Separate storage and computing |
| Programmatic interaction | All languages supporting JDBC/ODBC | REST API. Client libraries in Java, Python, Node.js, C#, Go, Ruby, and PHP |
| Data Ingestion | Load static data from AWS S3, EMR, DynamoDB table, and remote hosts. Load streaming data using Kinesis | Load data from Cloud Storage, Cloud Datastore backups, Cloud Dataflow, and streaming data sources. Use familiar data integration tools like Informatica, Talend, and others out of the box |
| Foundation for ML/AI | Use machine learning to deliver high throughput, irrespective of your workloads or concurrent usage. Redshift utilizes sophisticated algorithms to predict incoming query run times and assigns them to the optimal queue for the fastest processing. Predictive Analytics in AWS Redshift with SageMaker is in Preview | Besides bringing ML to your data with BigQuery ML, integrations with AI Platform and TensorFlow enable you to train powerful models on structured data in minutes with just SQL |
| Result caching | Use result caching to deliver sub-second response times for repeat queries | Writes all query results to a table either a temporary cached results table without charge or a permanent table with a storage charge |
| Maintenance | Automatically runs the VACUUM DELETE operation to reclaim disk space | Use the expiration settings to remove unneeded tables and partitions |
Performance
The performance is tricky on all data warehouse solutions. It depends on the size of the data table, schema complexity, and the number of concurrent queries, etc. The different benchmarks show different results. AWS Redshift provides a two-month free trial for the customer that has never created an Amazon Redshift cluster. GCP also gives $300 credits with its free tier account. So you should test with your benchmarks. For your reference, here are two performance results that show different stories:
- Cloud Data Warehouse Benchmark: Redshift, Snowflake, Azure, Presto, and BigQuery from Fivetran
- Interactive Analytics: Redshift vs Snowflake vs BigQuery from Periscope data
Security
Both data warehouse solutions provide very similar security features:
- Access controls: Both platforms leverage their IAM to set up roles and permissions
- Encryption at reset: Both platforms leverage their key management system to do database encryption and sever/client-side encryption on the load data files. BigQuery supports encryption by default. Redshift also supports HSM.
- Data in transit: Both platforms include virtual private cloud (VPC) and SSL connections
- Data loss prevention (DLP): AWS DLP service Macie doesn’t support Redshift. Google Cloud DLP service supports BigQuery.
Pricing Model
AWS Redshift’s pricing model covers both storage and computing cost. You can choose from RA3 (built on the AWS Nitro system with managed storage), Dense Compute, or Dense Storage nodes types. The cheapest node dc2.large with 160GB will cost you $0.25 per/hour. Please go to the AWS Redshift Pricing Calculator to calculate the cost. For example, with 1 dc2.large node on demand, 1TB additional backup storage, and 10TB Redshift Spectrum, the total monthly cost is $256.05 and you can pay upfront for the discount.
GCP BigQuery’s pricing model is complicated (e.g. active vs. long-term, flat-rate vs. on-demand, streaming inserts vs. queries vs. storage API). It separates the storage cost and query cost. Storage cost is $0.020 per GB per month and the query cost is $5 per TB. The storage is cheaper than AWS Redshift but the query costs can add up quickly. Please go to the GCP Pricing Calculator then select BigQuery to estimate the cost.
Conclusion
Both AWS Redshift and GCP BigQuery are highly scalable enterprise data warehouse solutions to make data analytics more productive with unmatched price-performance. Both data warehouse cloud solutions take care of infrastructure management and database administration responsibilities. So you can focus on business needs using familiar SQL. There are some differences between AWS Redshift and GCP BigQuery. But there are far more similarities from the users’ standpoint.
I like AWS Redshift’s Spectrum concept that is similar to the external tables in Oracle. Using Amazon Redshift Spectrum, you can efficiently query and retrieve structured and semistructured data from files in AWS S3 without having to load the data into Redshift. I’m impressed with BigQuery ML. You can use standard SQL queries to create and execute machine learning models. It increases ML development speed by eliminating the need to move data.
From the cost standpoint, BigQuery’s pricing model is unpredictable and complex on query operations. Redshift, on the other hand, is predictable, simple and encourages data usage and analytics. But BigQuery is much simpler to use than Redshift with its completely serverless, an in-memory BI Engine and machine learning built-in. However, Redshift gives the level of control over your data warehousing setup and performance tunning. So the correct decision depends on your use cases, cost and performance benchmark.



